People often assume that every software engineer knows how the internet, protocols, and network work. Even though I understand it’s essential to comprehend how those topics work, I believe every person has their way of learning, and sometimes they skip them for different reasons. However, this lack of knowledge might directly impact implementing REST APIs or web page behaviours.
This article will cover the fundamental parts of the HTTP protocol, its anatomy, and how it helps design more pleasing APIs.
Overview
HTTP (Hypertext Transfer Protocol) is an extensible application-layer client-server communication protocol sent over a reliable transport layer, usually a TCP connection. Essentially, it’s the backbone of what we know as “the internet”.
The protocol uses a text-based model where you have requests and responses. In a simplified way, a recipient sends an HTTP request - let’s say, a web browser or search engines -a server handles it and responds with a resource which can be plain text, a video, an HTML page, whatever.
Although there are many other components between a request and response, such as physical infrastructure (modem, routers, and others) and proxies, I’ll focus on the application layer built on top of it: HTTP, in our case.
Overall aspects
Simplicity & extensibility
The HTTP has gone through many evolutions for the past 30 years. First, it started as a one-line protocol with a small amount of information. Then, after the project went public, browsers and servers introduced HTTP/1 with new key elements, such as headers, status codes, and versioning.
Those elements had a significant impact on the protocol extensibility. With headers, for instance, we can send and receive metadata where you can enhance requests and responses with more detailed information.
As a result, implementing new features is more accessible, for instance, by an agreement between client and server using those headers. That’s extensibility.
Statelessness
An HTTP transaction doesn’t have any relationship with the previous ones. RFC7230 describes the protocol as a “stateless protocol, meaning that each request message can be understood in isolation”. Therefore, an individual request must contain all the necessary data for the server to process it.
Statelessness can be a restriction. For example, you don’t want to put your username and password every time you go to your e-mail provider. In a stateless context, we can achieve that by leveraging HTTP extensibility: using cookies that allow each transaction to share the same context.
Connections
As I mentioned earlier, according to the specification, HTTP requires a reliable connection to transport data. In other words, it needs a way to exchange messages without any risk of losing them.
HTTP doesn’t necessarily need an underlying connection-based protocol, and it just requires to be reliable. Therefore, HTTP relies on o TCP, a connection-based transport protocol.
In short, TCP ensures a packet will be fully delivered by using acknowledgement and retransmission strategies. Hence, it sacrifices speed to improve reliability. That’s one reason why some studies, such as QUIC by Google, come up as an alternative to TCP.
Media independence
HTTP provides a uniform interface for interacting with a resource, regardless of its type, nature, or implementation, via the manipulation and transfer of representations. RFC 7231
The client can send any data over HTTP to the server if they have an agreement on how to handle it. In practice, there’s a content type negotiation between server and client, usually achieved by using two specific headers: Content-Type and Accept.
They use Internet Media Types and, combined with other headers, such as Content-Length and Content-Description, can provide more information about exchanged data. For a better understanding of content negotiation and media types, see RFC2046.
Requests and responses anatomy
We make a lot of requests every day. For example, to access this blog, you made an HTTP request and, now, you’re reading the content. The goal of an HTTP request is to access a resource on the server and, then, the client reads a response, in this case, a blog post.
Breaking a request into steps, we would have:
- Establish a TCP connection
- Send an HTTP message
- Read the HTTP response from the server
- Close or re-use the connection for further requests
HTTP Request
Diving deeper, say we’re accessing this post using curl, this is the structure of a request:
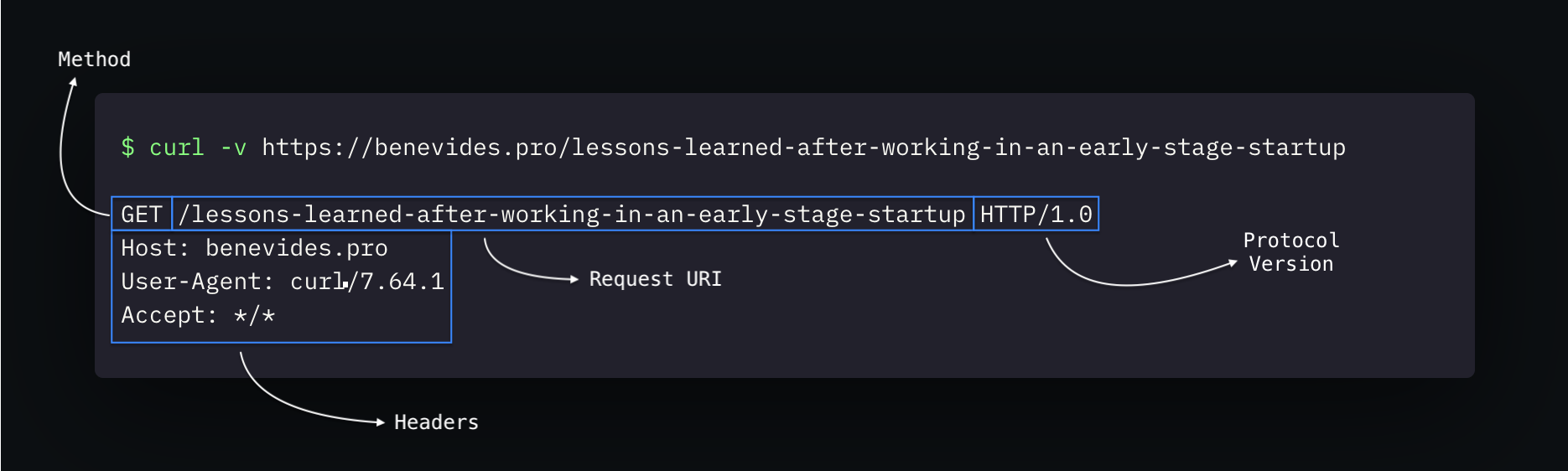
Method
Each request needs a method that describes which operation the client will perform on the server. There’s a set of standard HTTP methods in different protocol versions defined in an RFC, but you can also extend and create others if the server knows how to handle it.
They can be safe, idempotent or both.
Safe means that it doesn’t modify the state on the server, and they’re always idempotent. Good examples are read-only operations like GET, OPTION and HEAD.
Idempotency conveys that the client can send the same request once or several times, and the server will keep the same state. The specification defines that PUT, DELETE and all safe methods are idempotent.
Regardless, keep in mind that you’ll likely face servers that don’t implement it correctly.
Request URI
URI means Uniform Resource Identifier, and it identifies a resource on a remote server. Likewise, it might contain a “query string” - a set of encoded key-values - with additional information that servers can use for some purpose, such as filtering or tracking.

Protocol Version
Well, self-explained. Most likely HTTP1.1 or, now, HTTP/2.
Headers
List of key-value pairs. It holds relevant information for the server and has a set of standard headers defined in an RFC. Like HTTP methods, you can create new ones, though, as long as there’s an agreement between client and server about that.
Message Body
A message-body is the request or response content. Although it’s present on both parts, there are different rules for each other. As RFC2616 describes:
“The presence of a message-body in a request is signaled by the inclusion of a Content-Length or Transfer-Encoding header field in the request’s message-headers. A message-body MUST NOT be included in a request if the specification of the request method (…) For response messages, whether or not a message-body is included with a message is dependent on both the request method and the response status code (section 6.1.1). All responses to the HEAD request method MUST NOT include a message-body, even though the presence of entity-header fields might lead one to believe they do. All 1xx (informational), 204 (no content), and 304 (not modified) responses MUST NOT include a message-body. All other responses include a message-body, although it MAY be of zero length”.
HTTP Response
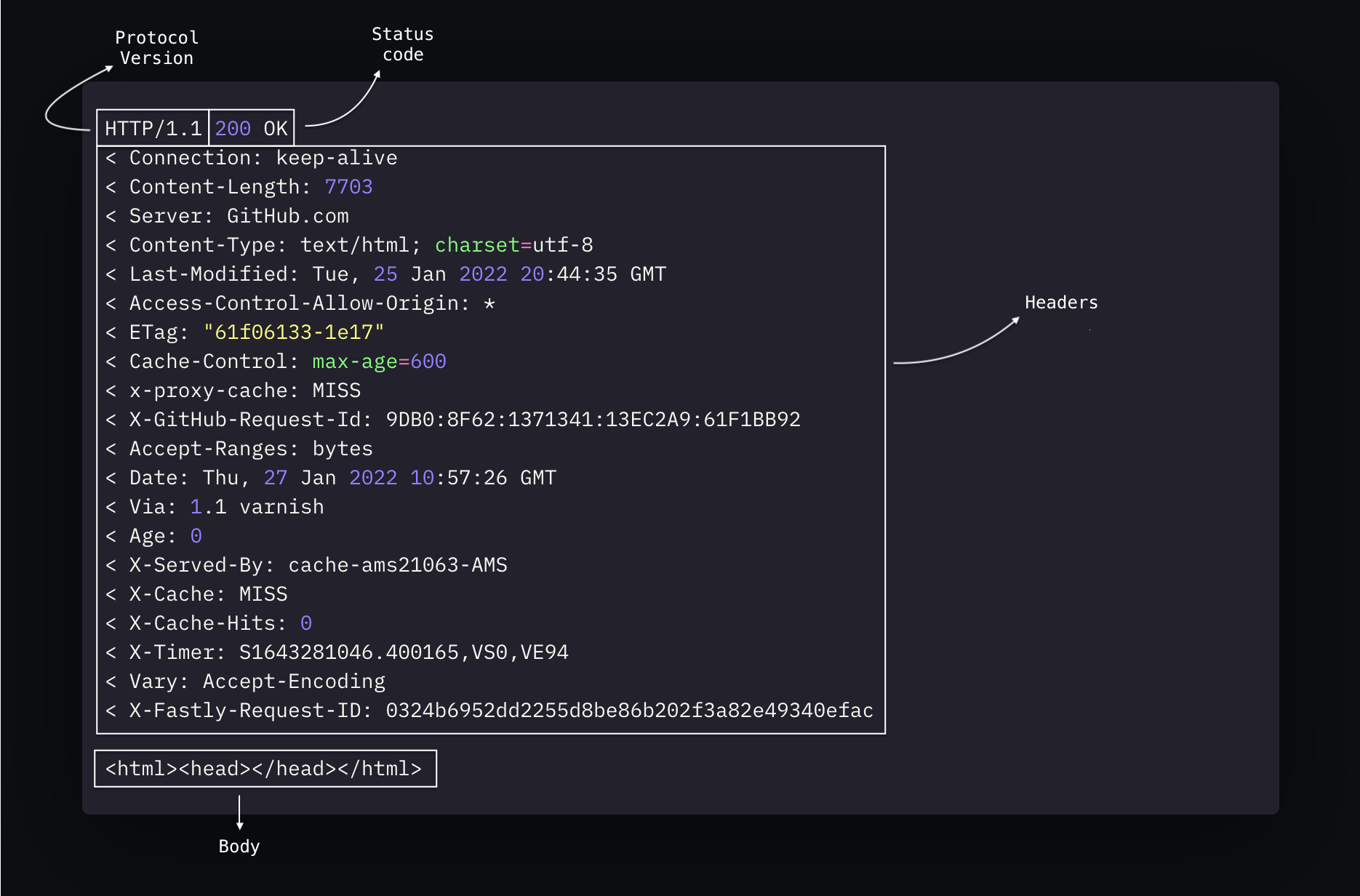
A response has pretty much the same elements as an HTTP request. However, in this example, we can see how the protocol extensibility empowers exchanging data between client and server by using many headers that aren’t from the standard ones.
Likewise, just like an HTTP request, it may have a message-body, which contain the fetched resource from the server in a representation defined in the Content-Type header.
Status code
Finally, here comes the status code. It’s a three-digit number followed by a reason phrase. It indicates if the request was successful or not, always sending a better explanation on why.
It helps the client handle the response properly, and teamed up with headers and message-body, can provide meaningful data.
Why does it matter?
Web development has many frameworks living around, and many of them abstract everything from HTTP, which is good in terms of productivity. Nevertheless, you should know what your preferred web framework is doing behind the scenes. You would be surprised by how many parts can be optimised by reducing call chains, for instance, or how fast you can debug that horrible bug you’ve been fighting.
In the same way, knowing when to use HTTP methods, status codes, and content negotiation avoid bizarre behaviours on webpages or not-so-well designed APIs.
As an engineer, you’ve probably seen something about RESTful APIs. The well-known REST stands for an architectural style that allows developers to build web services and utilise existing communication protocols. Although you can use any existing protocol, you’ll more likely use HTTP for web APIs. Therefore, you can’t build web APIs without knowing HTTP basics.
Finally, the protocol HTTP has kept evolving over the past years. A new version called HTTP/2 has brought us many new features, and it opens up new opportunities for optimisations by reducing latency, improving error handling, multiplexing and much more.